


DeepSeek Open Source Week: A Technical Journey

In what I consider one of the most exciting bursts of innovation this February (yes, we are only two months into 2025!), DeepSeek has spent a full week—spanning five consecutive days—open-sourcing core components of its AI infrastructure. Each release not only showcases state-of-the-art engineering but also demonstrates a genuine commitment to sharing knowledge with the community. In this article, I’ll walk you through a detailed, chronological recap of these releases, explain the technical innovations behind them (with references to key diagrams), and share my personal thoughts on why these contributions are so compelling.
Day 1: FlashMLA – Accelerating LLM Decoding
Link: https://github.com/deepseek-ai/FlashMLA
Overview:
FlashMLA is an efficient decoding kernel designed for multi-query and grouped-query attention (MLA) on NVIDIA Hopper GPUs (H100/H800). It’s built to boost inference for large language models (LLMs), especially when handling variable-length sequences—a common challenge in production environments where input sizes can vary dramatically.
Technical Breakdown:
Paged Key-Value (KV) Cache:
Instead of using one giant, monolithic cache, FlashMLA breaks the KV cache into 64-entry blocks. This block-based or “paged” approach allows the system to allocate memory dynamically based on the sequence length. The result? Less fragmentation and more efficient use of memory since only the necessary parts of the cache are active.BF16 & FP16 Support and Throughput Optimization:
By supporting both BF16 and FP16 data types, FlashMLA strikes a solid balance between accuracy and speed. This dual-precision capability allows the kernel to tap into the full power of Hopper’s tensor cores, achieving around 3000 GB/s of memory bandwidth and roughly 580 TFLOPS on H800 GPUs—essential figures when every bit of throughput counts in compute-heavy tasks.Multi-Query and Grouped-Query Attention:
A key feature of FlashMLA is its implementation of the MLA attention pattern. In simple terms, one key-value head is shared across multiple query heads. This design choice significantly cuts down on memory bandwidth requirements and reduces computation costs during inference—a huge win for real-time applications.Tiled Execution Strategy:
Taking inspiration from FlashAttention, FlashMLA uses a tiled execution approach that optimizes memory access. By carefully designing tile sizes to make the most of SRAM, data is processed in efficient chunks, which helps reduce the latency involved in fetching data from memory.Advanced Scheduling & Split KV Processing:
The kernel features a smart tile scheduler (via functions likeget_mla_metadata) that pre-calculates execution patterns. This helps distribute workloads evenly across GPU streaming multiprocessors (SMs). Combined with a “split KV” approach, FlashMLA efficiently handles long token sequences without unnecessary delays.Low-level CUDA Optimizations & CUTLASS Integration:
Drawing inspiration from FlashAttention and NVIDIA’s CUTLASS library, the implementation includes fine-tuned CUDA optimizations. These reduce instruction overhead and maximize parallel execution across CUDA cores, with optimized GEMM operations and careful shared memory management underpinning its high performance.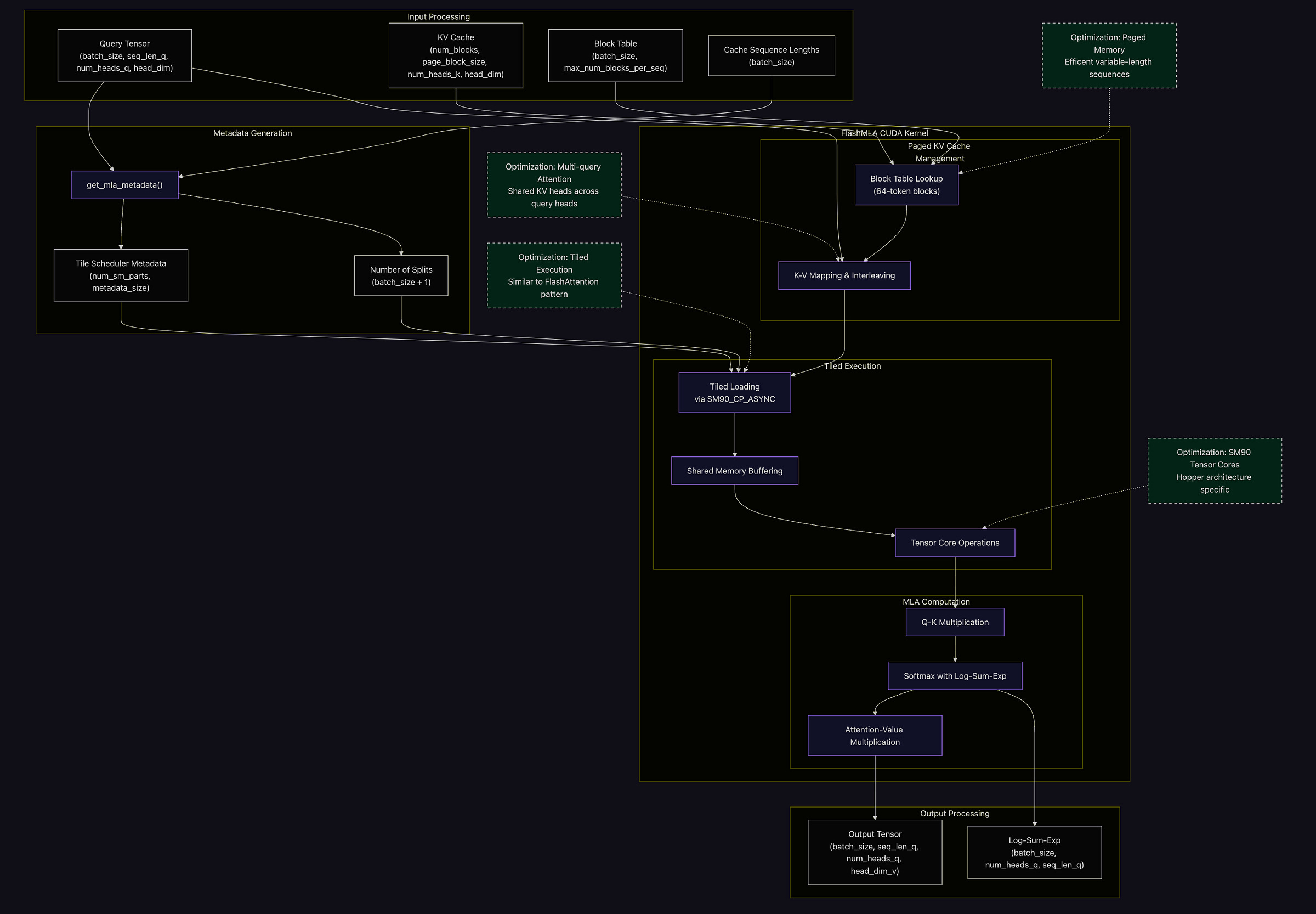
Figure 1: FlashMLA architecture overview. The system optimizes Multi-query attention (MLA) operations for LLM inference on Hopper GPUs using block-based paged memory management, tiled execution algorithm, and tensor core optimizations. The architecture achieves up to 3000 GB/s throughput and 580 TFLOPS on H800 SXM5 GPUs. Memory Management and Python Interface:
FlashMLA is built on a well-structured paged memory design, complete with block tables that ensure efficient handling of variable-length sequences. Additionally, its simple Python API (with functions likeget_mla_metadataandflash_mla_with_kvcache) makes it easy for developers to integrate high-performance kernel execution into their projects.Benchmarking and Cross-Platform Considerations:
Extensive benchmarking has shown that FlashMLA outperforms traditional approaches, including those based on PyTorch and Triton. Although it’s optimized for NVIDIA Hopper GPUs, community-supported adaptations extend its usability to other platforms as well.Performance Characteristics:
FlashMLA achieves up to 3000 GB/s in memory-bound scenarios and about 580 TFLOPS when computation is the limiting factor—metrics validated on H800 SXM5 GPUs using CUDA 12.8. These numbers underscore its potential to dramatically accelerate LLM inference, particularly for applications requiring rapid, efficient processing of variable-length sequences.

Personal Take:
The dynamic, paged KV cache is a practical fix to long-standing memory fragmentation issues in LLM inference. The integration of multi-query attention, tiled execution, and advanced scheduling shows a deep understanding of both algorithmic needs and hardware capabilities. For me, FlashMLA is a good example of how thoughtful, low-level optimizations can deliver real-world benefits by pushing inference speeds to new heights while keeping resource utilization in check.
Day 2: DeepEP – Optimizing Communication for MoE Models
Link: https://github.com/deepseek-ai/DeepEP
Overview:
DeepEP (Deep Expert Parallelism) is a communication library engineered specifically for Mixture-of-Experts (MoE) models. By addressing the notorious communication bottlenecks in traditional MoE architectures, it paves the way for efficient data dispatch and combination across expert sub-networks—both critical for scaling training and inference in large language models.
Technical Breakdown:
Dual-Mode Communication Engine:
At its core, DeepEP introduces a dual-mode engine that caters to two distinct operational scenarios:High-Throughput Mode:
By combining NVLink for intra-node transfers with RDMA for internode communication, this mode ensures rapid data shuffling among experts even as the system scales across multiple GPUs. Specialized CUDA kernels (NVLink Kernels and RDMA Kernels) work together to maintain high bandwidth.Low-Latency Mode:
For real-time inference where every millisecond matters, DeepEP’s low-latency mode employs dedicated kernels that minimize delays during both data dispatch and combination—achieving latencies as low as 163–194μs for dispatch and 318–369μs for combining operations.
Figure 2: DeepEP: A specialized GPU communication library for Mixture-of-Experts models, providing high-throughput and low-latency all-to-all operations across NVLink and RDMA domains with optimized expert parallelism for both training and inference.
Precision Support – FP8 & Beyond:
DeepEP natively supports FP8 precision, which greatly reduces data bandwidth needs. Coupled with BF16 support, this design ensures high training accuracy despite the lower bit-width—a crucial factor when hundreds of experts interact simultaneously.Core Architectural Components and Buffer Management:
DeepEP’s architecture is built around a robust Python API that interfaces with a C++/CUDA backend. Key components include:A Buffer Class that handles memory for NVLink and RDMA operations with smart allocation and synchronization (using a Task FIFO and dedicated CUDA Workspace).
Dispatch and Combine Operations that separately manage the routing of input tokens to experts and the merging of outputs into a unified tensor.
A standout feature is its hook-based approach to overlapping communication with computation. Instead of pausing computations for data transfers, DeepEP pipelines communication tasks asynchronously, freeing up GPU SMs to work continuously. An SM Control module dynamically allocates resources based on the workload, ensuring smooth operations.
Additional Optimizations and Network Configuration:
DeepEP also leverages some advanced, even unconventional, optimizations:Undefined-Behavior PTX Optimizations: Utilizing carefully validated, undefined-behavior PTX instructions (such as the read-only
ld.global.ncvariants) allows for faster memory reads without compromising correctness.Custom NVSHMEM & IBGDA Integration: DeepEP integrates modified NVSHMEM for more efficient RDMA operations, incorporating InfiniBand GPUDirect Async (IBGDA) for traffic isolation and adaptive routing—a crucial factor when scaling out to dozens of experts.
Group-Limited Gating Algorithm: Implemented as per DeepSeek-V3 research, this algorithm further optimizes bandwidth forwarding between different communication domains, ensuring that the expert dispatch is as balanced as possible.

Personal Take:
DeepEP’s dual-mode engine isn’t just about raw speed—it’s about intelligently managing diverse communication patterns in large-scale MoE setups. The combination of precise buffer management, asynchronous overlapping, and advanced kernel optimizations shows a deep grasp of both hardware and software challenges in large-scale MoE systems. DeepEP stands out as a robust solution for tackling the communication bottlenecks that can hinder distributed training.
Day 3: DeepGEMM – A Lean FP8 GEMM Library
Link: https://github.com/deepseek-ai/DeepGEMM
Overview:
DeepGEMM is a specialized CUDA library for high-efficiency FP8 general matrix multiplications (GEMMs) on NVIDIA Hopper GPUs. With a minimalist codebase of roughly 300 lines, it handles both standard dense GEMM operations and specialized grouped GEMMs for MoE architectures. Using cutting-edge techniques like runtime JIT compilation, advanced scheduling, and optimized memory management via Hopper’s TMA features, DeepGEMM delivers exceptional throughput without sacrificing numerical stability. It’s a perfect example of how a lean design can yield powerful performance.

Technical Breakdown:
FP8 Arithmetic with Two-Stage Accumulation:
DeepGEMM supports bothfp8_e4m3andfp8_e5m2formats, dramatically reducing memory usage and computation cost. To preserve numerical stability despite the lower precision, it uses a two-stage accumulation process. First, intermediate results are gathered in fast registers; then, these sums are promoted to a higher precision (typically BF16), which helps mitigate any precision loss.Just-In-Time (JIT) Compilation:
One of DeepGEMM’s core strengths is its fully JIT-based design. Kernels are compiled at runtime, allowing the system to treat GEMM shapes, block sizes, and pipeline stages as constants known at compile time. This approach not only avoids the overhead of pre-compilation and excessive template use but also automatically selects optimal parameters like block dimensions, warpgroups, and TMA cluster sizes.Support for MoE Layouts and Dense GEMMs:
Recognizing the growing importance of MoE architectures, DeepGEMM supports both standard dense tensor layouts and specialized grouped GEMM formats. It offers options for contiguous and masked grouped GEMMs, ensuring that it can integrate seamlessly into various AI pipelines as a lightweight, high-performance alternative.Optimized Kernel Execution and Memory Management:
DeepGEMM leverages Hopper’s Tensor Memory Accelerator (TMA) to optimize data transfers between global and shared memory. The library employs tiled execution strategies, where TMA utilities load matrices and scaling factors into shared buffers, followed by processing through a pipeline that involves both tensor core operations and CUDA-core promotion. In addition, an advanced block scheduler optimizes work distribution across streaming multiprocessors (SMs) using techniques such as rasterization and L2 cache reuse.
Moreover, warp specialization is used to overlap data movement with computation, ensuring maximum hardware utilization even during the promotion stage. Non-traditional block sizes (i.e., non-power-of-2) are supported to further optimize SM occupancy for specific matrix dimensions.Execution Flow and Scaling Mechanisms:
Starting from an API call, the process flows through JIT compilation (if needed), then through block scheduling, TMA descriptor setup, and pipeline execution across both tensor cores and CUDA cores, finishing with result storage. Per-channel and block-level scaling mechanisms carefully control the scaling of FP8 operations to ensure numerical accuracy throughout the computation.
Personal Take:
In my view, DeepGEMM stands as a stellar example of how focused, well-engineered code can deliver performance on par with—or even surpass—more bloated libraries. The way it marries runtime JIT compilation with a two-stage accumulation process for FP8 arithmetic is both technically elegant and immensely practical.
Day 4: DualPipe & EPLB – Enhancing Parallelism and Load Balancing
Link: https://github.com/deepseek-ai/DualPipe / https://github.com/deepseek-ai/EPLB
Overview:
DualPipe introduces a novel bidirectional pipeline parallelism approach, as described in the DeepSeek-V3 Technical Report. Its main objective is to overcome the pipeline stalls and “bubble” time that are typical in traditional pipeline parallelism. By orchestrating simultaneous forward and backward passes across micro-batches, DualPipe maximizes GPU utilization and minimizes idle periods, leading to a significant boost in throughput.
Technical Breakdown:
Bidirectional Data Flow:
Traditional pipeline methods operate in a single direction, often leading to idle time while waiting for subsequent stages to complete. DualPipe innovates by dividing the pipeline into two halves, with each GPU hosting dedicated forward and backward modules. This design allows the forward pass of one micro-batch to overlap with the backward pass of another, effectively reducing pipeline bubbles.Advanced Scheduling Algorithm:
The heart of DualPipe is its sophisticated scheduling mechanism, which dynamically assigns micro-batches to available GPU resources. This scheduler not only minimizes latency but also balances workloads across GPUs by coordinating point-to-point communications using non-blocking collectives and optimized tensor configurations.Core Architecture and Communication Modules:
DualPipe is structured around a core controller that integrates with a dedicated communication module, model adapters, and framework compatibility utilities. The communication module manages both intra-node and inter-node data transfers, ensuring that tensor data flows efficiently between pipeline stages. Custom adapters (e.g., for transformer layers or vision models) allow seamless integration with various architectures, making the approach highly versatile.

EPLB:
Complementing DualPipe, EPLB addresses workload imbalance in MoE systems. It monitors the load on each expert in real time and redistributes tasks to prevent bottlenecks, ensuring that every GPU or node contributes effectively. By employing both hierarchical and global load balancing strategies, EPLB optimizes resource utilization throughout the training process.

Personal Take:
DualPipe and EPLB together are like the yin and yang of distributed training—one refines the flow of computation while the other ensures balanced load distribution. I find their combined approach very exciting, as it smartly tackles both compute and communication challenges simultaneously. It’s a clear reminder that solving complex problems often requires addressing multiple angles at once.
Day 5: 3FS & Smallpond – Rethinking Data Infrastructure
Link: https://github.com/deepseek-ai/3FS / https://github.com/deepseek-ai/smallpond
Day 5: 3FS & Smallpond – Rethinking Data Infrastructure
Overview:
On the final day of DeepSeek’s Open Source Week, two additional tools were unveiled to tackle one of the remaining bottlenecks in AI development—data management. 3FS (Fire-Flyer File System) is a high-performance, distributed file system that decouples storage from compute, enabling applications to harness NVMe SSDs and RDMA networks for incredible throughput. Smallpond sits on top of 3FS as a lightweight data processing framework, streamlining data workflows and efficiently managing PB-scale datasets. Together, they form a comprehensive solution that smooths out data I/O bottlenecks, facilitating faster model training and inference.
Technical Breakdown:
3FS – High-Performance Distributed File System:
3FS is engineered to deliver extraordinary throughput, with benchmarks reporting up to 6.6 TiB/s on large clusters. Its key innovations include:
Disaggregated Architecture:
3FS decouples storage from compute nodes, allowing it to fully leverage NVMe SSD bandwidth and RDMA networking. This design means that storage resources are accessed in a locality-oblivious manner, thereby minimizing I/O bottlenecks during training and inference.
Figure 6: 3FS: A high-performance distributed file system using chain replication and disaggregated architecture to provide strong consistency and massive throughput for AI workloads. Strong Consistency and Scalability:
The file system employs a robust Metadata Service that uses a transactional key-value store (FoundationDB) to manage file semantics. Coupled with a Cluster Manager that handles membership and service discovery, 3FS maintains strong consistency across nodes—crucial for operations like checkpointing and distributed caching. The chain replication protocol ensures that every write is reliably propagated and acknowledged, while read requests can be balanced across multiple targets to optimize throughput.Optimized Data Placement and Zero-Copy I/O:
By using chain tables and a balanced incomplete block design, 3FS smartly allocates data across storage nodes. This, combined with asynchronous zero-copy APIs (inspired by Linuxio_uring), minimizes RPC overhead and leverages RDMA for near-instantaneous data transfers. Such optimizations allow the system to achieve peak performance figures in both aggregate throughput and sorted data benchmarks (e.g., GraySort).

Smallpond – A Lightweight Data Processing Framework:
Built to sit atop 3FS, Smallpond orchestrates data workflows with simplicity and efficiency. Its architecture comprises:
Session-Based Operation and Logical Query Planning:
Smallpond adopts a session-based model where users initialize a session (viasmallpond.init()), which then manages resource allocation and task scheduling throughout the data processing lifecycle. The framework provides a DataFrame API reminiscent of Pandas or Spark, enabling operations such asread_parquet(),filter(), andpartial_sql(). The logical planning layer constructs query plans that are then optimized and translated into physical tasks.Execution Engine and Distributed Computing Model:
The execution engine schedules tasks across worker nodes using Ray or MPI, ensuring that operations can scale with the available hardware. It includes modules for task scheduling, queue management, and executor orchestration. This distributed design not only facilitates handling PB-scale datasets but also enables seamless integration with advanced processing engines like DuckDB, PyArrow, and Polars.I/O and Memory Management Innovations:
Smallpond leverages Apache Arrow for fast in-memory columnar data representation and supports efficient file I/O through its integration with 3FS. Features like NUMA-aware execution and configurable memory allocators further boost performance.Advanced Data Partitioning and SQL Integration:
Intelligent partitioning strategies, such as hash-based partitioning, and support for SQL queries (viapartial_sql()) allow users to combine the expressiveness of SQL with the flexibility of Python—making it easier to work with complex datasets.

Personal Take:
The pairing of 3FS and Smallpond is especially intriguing to me. While much of AI research often emphasizes computational innovations, these tools remind us that data management is equally crucial. With 3FS, DeepSeek has effectively addressed the I/O bottleneck by creating a disaggregated, high-throughput storage solution that maintains strong consistency—vital for robust training and inference. Meanwhile, Smallpond provides a lightweight yet powerful framework for processing massive datasets, integrating smoothly with tools like DuckDB and Ray. Together, they offer an end-to-end solution that tackles one of the last major challenges in scaling AI systems, and I believe they could be a game changer for both model deployment and training pipelines.
Final Thoughts
DeepSeek’s Open Source Week is far more than a series of repository releases—it’s a comprehensive blueprint for modern AI infrastructure. From low-level GPU optimizations (FlashMLA and DeepGEMM) to high-level communication and load balancing (DeepEP, DualPipe, and EPLB), and finally to advanced data management (3FS and Smallpond), each component addresses a crucial part of the AI pipeline.
What I find most compelling is the thoughtful integration of these tools. Rather than a scattergun approach, DeepSeek has released components that naturally complement each other. The technical ingenuity behind these projects is matched only by their practical value. For anyone involved in large-scale model training or AI infrastructure, these open-source releases provide not only cutting-edge performance but also a chance to learn from—and contribute to—a vibrant ecosystem.
In my view, the future of AI development hinges on such open, collaborative approaches. DeepSeek has set a high standard with these releases, and I’m excited to see how the community builds on this solid foundation.